



Google has unveiled a major shift in how voice search works – a new system called Speech-to-Retrieval (S2R). Instead of transcribing speech into text first and then searching, S2R interprets spoken queries directly and retrieves results.

What is S2R and How Does It Work?
Voice search usually follows a two-step “cascade” model process: first it listens to your words and then turns them into text and runs a text search. The problem is that if the speech recognition makes a tiny mistake, the search results can go wrong.
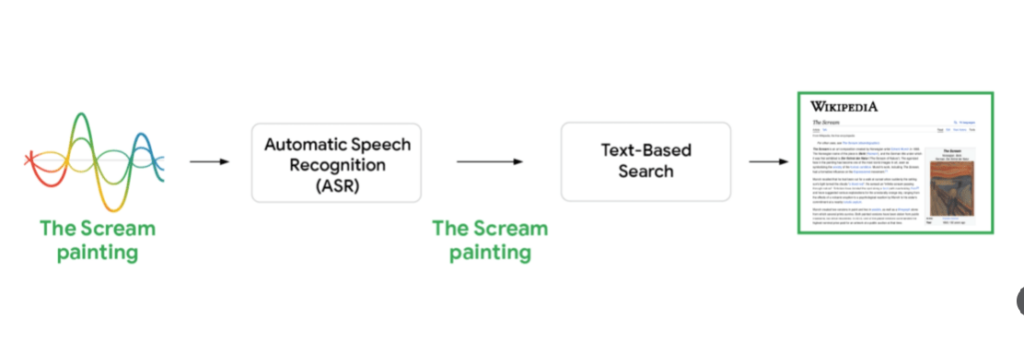
With S2R, Google seems to fix that mistake. It listens, figures out what you mean, and then finds answers, following a more direct path from your voice to relevant information.
S2R is based on a dual-encoder neural model: the audio encoder turns the spoken words into an “audio embedding”, a tool that captures the meaning behind what’s said. Then a document encoder generates relevant content (web pages, documents, etc.).
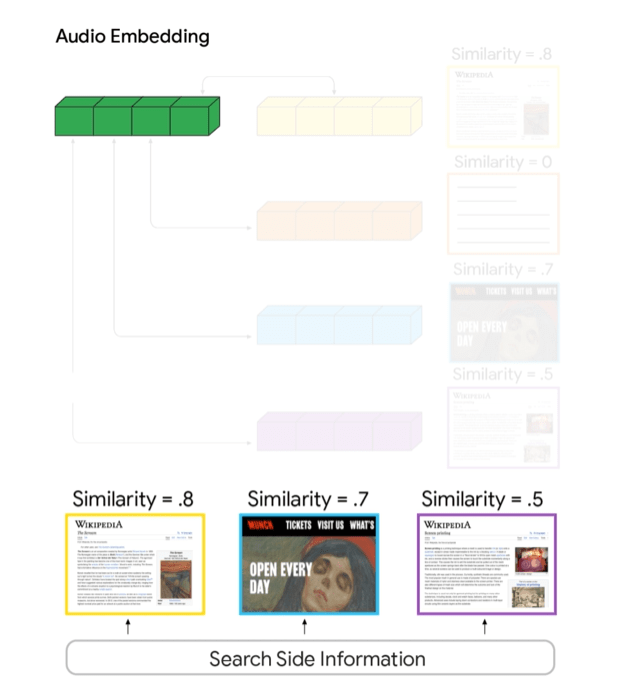
When you speak, the system produces the audio embedding and uses it to search for documents with high similarity scores. The results are then ranked using Google’s existing ranking systems.
Why S2R Matters
According to Google, S2R Search provides better accuracy and less errors: the system doesn’t rely on a perfect text transcript anymore, which means fewer transcription mistakes. With smarter understanding S2R cares more about intent than exact words, which helps with unintelligible speech.
In tests, S2R showed better results than traditional voice search systems and came close to what would be possible with perfect speech transcription.
New Era of Voice Search
Google says S2R is already used as a voice search across multiple languages. The company also released a dataset called Simple Voice Questions (SVQ) – short spoken questions in 17 languages across 26 regions that will help researchers to evaluate and improve the system.
This move shows Google’s step toward voice systems that “understand” what you want, not just what you say. This new invention marks the beginning of the new era of voice search where speech isn’t just transcribed but also understood.